

简介
当您在阿里云容器服务中使用GPU ECS主机构建Kubernetes集群进行AI训练时,经常需要知道每个Pod使用的GPU的使用情况,比如每块显存使用情况、GPU利用率,GPU卡温度等监控信息,本文介绍如何快速在阿里云上构建基于Prometheus + Grafana的GPU监控方案。
Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。从 2012 年开始编写代码,再到 2015 年 github 上开源以来,已经吸引了 9k+ 关注,2016 年 Prometheus 成为继 k8s 后,第二名 CNCF(Cloud Native Computing Foundation) 成员。2018年8月 于CNCF毕业。
作为新一代开源解决方案,很多理念与 Google SRE 运维之道不谋而合。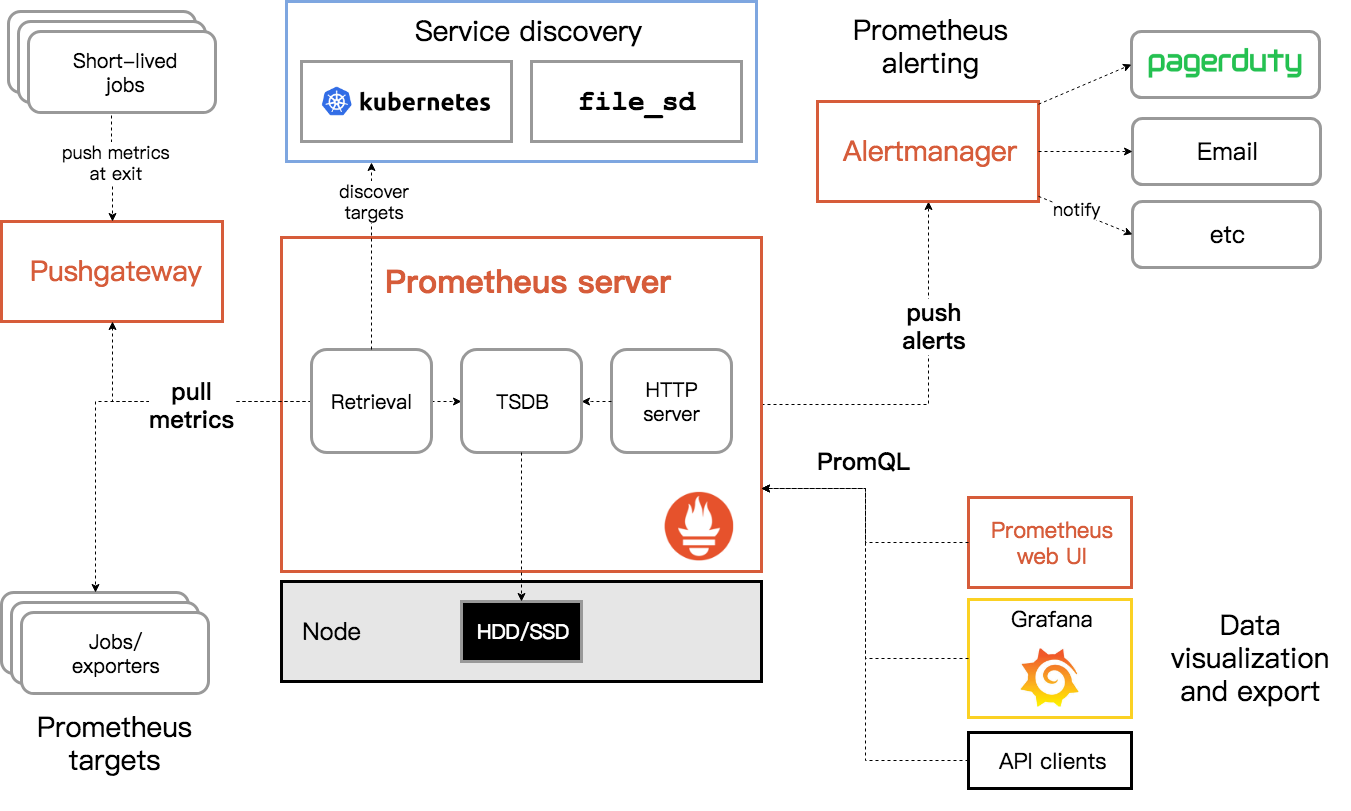
操作
前提:您已经通过阿里云容器服务创建了拥有GPU ECS的Kubernetes集群,具体步骤请参考:尝鲜阿里云容器服务Kubernetes 1.9,拥抱GPU新姿势。
登录容器服务控制台,选择【容器服务-Kubernetes】,点击【应用-->部署-->使用模板创建】: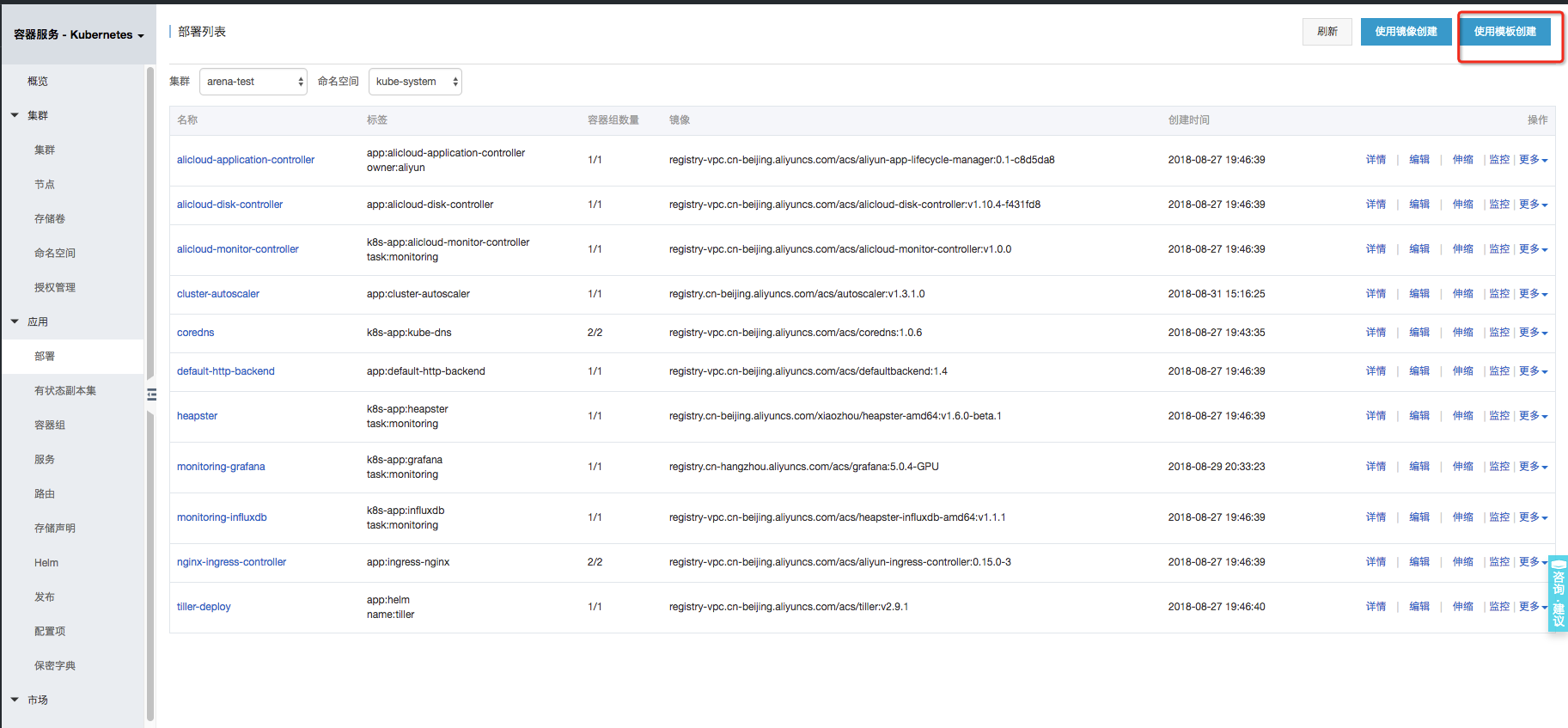 选择您的GPU集群和Namespace,命名空间可以选择kube-system,然后在下面的模板中填入部署Prometheus和GPU-Expoter对应的Yaml内容。
选择您的GPU集群和Namespace,命名空间可以选择kube-system,然后在下面的模板中填入部署Prometheus和GPU-Expoter对应的Yaml内容。